이 글에 포함된 모든 사진 자료들은
<원리부터 설계까지 쉽고 명확한 컴퓨터구조> (서태원 지음)
에서 가져왔습니다.
Pipeline CPU란
“
pipeline CPU란, single-cycle CPU 구조를 여러 stage로 나누어, 각 부분을 동시에 활용되게끔 하는 것이다.
(아래 사진 참고)

single-cycle CPU에서는, 하나의 instruction이 완료되고 나서야 그 다음 instruction을 수행한 데 비해,
pipeline CPU의 경우, 매 clock cycle의 각 stage에서는 다른 instruction이 실행되고 있다.
(아래 사진 참고)


“
전형적인 것은 5-stage pipeline CPU이며, 각 stage는 다음과 같다:
- IF(Instruction Fetch): 명령어를 읽는 단계
- ID(Instruction Decoding): 명령어를 해석하고 source operand를 준비하는 단계
- EXE(Execution): 명령어를 실행하는 단계
- MEM(Memory Access): 메모리에 접근하는 단계
- WB(WriteBack): 레지스터 파일을 업데이트하는 단계
“
이같이 단계를 나누려면, 나누고자 하는 곳에 flip flop을 삽입하여야 한다. 또한 이를 통해 데이터뿐만 아니라 control 신호도 함께 다음 단계로 전달해야 한다.
(아래 사진 참고)

“
하지만 이러한 pipeline CPU 구조는 Hazard를 발생시키므로, 이에 대한 해결책이 필요하다.
Data Hazard란
“
Data hazard는 instruction 실행 과정에서의 data depencence 때문에 일어난다.
(data dependence: 앞의 명령어가 변경하는 레지스터를 뒤의 명령어가 사용하는 경우)
여기서 "앞의 명령어"가 무엇인지에 따라 경우가 나뉜다.
“
앞의 명령어가 "데이터 처리 명령어"인 경우
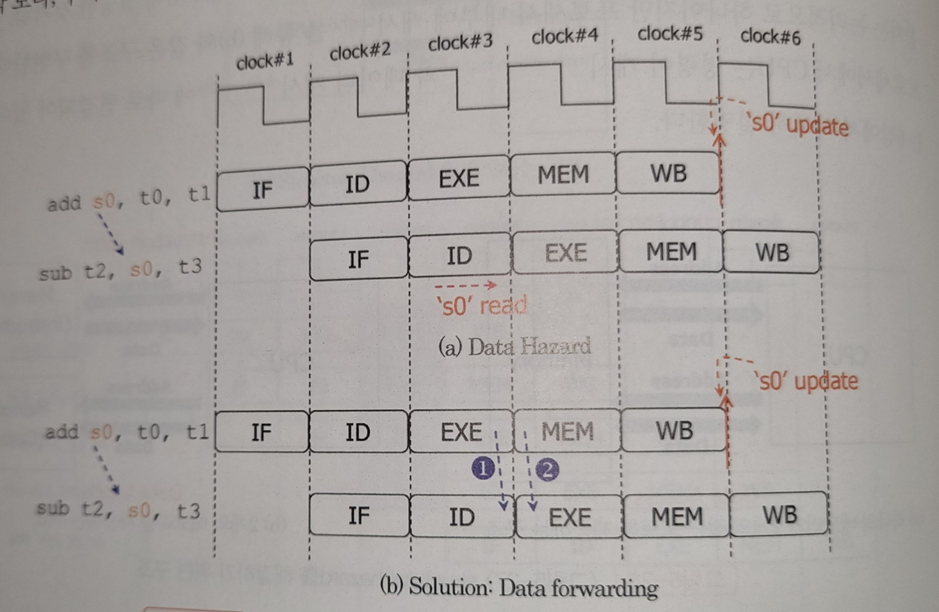
“ 문제점
예를 들어 위와 같이 명령어가 순서대로 있을 때,
첫 명령어의 연산 결과로 인해 s0가 변경되고, 다음 명령어는 이 s0를 가지고 연산한다.
그런데 첫 명령어에서 s0가 업데이트되는 시점은 WB의 끝, 즉 clock #5의 끝인데,
다음 명령어가 s0를 사용하는 것은 EXE부터, 즉 clock #4의 시작부터이다. 즉 이것이 시간 상 먼저 일어나버리는데, 이 시점에는 아직 첫 명령어에 의한 s0 업데이트 이전이므로,
의도와 다른 해석이 이루어지고 만다.
“ 해결책
그런데 실제로 첫 명령어에서 새로운 s0 값이 결정되는 것은, WB의 끝까지 기다릴 필요 없이, 첫 명령어의 EXE 과정에서 ALU를 거친 직후이다. 따라서 이 값을 미리 다음 명령어의 EXE에서 활용되기 이전에 전달해주면 해결되며, 이것이 Data forwarding이다.
이러한 Data Forwarding이 필요한 모든 경우는 다음과 같다.

“ 이러한 data forwarding 여부를 결정하기 위해선 data hazard의 발생 여부를 먼저 판단해야 한다. 이는 data dependency 관계에 있는 두 명령어 중 앞선 명령어의 destination register와 후속 명령어의 source register를 비교하여, 동일한 경우 hazard가 발생한다고 판단하여 필요한 control 신호를 만든다.
“
앞의 명령어가 "load 명령어"인 경우
“ 이 경우에는 위의 방법만으로는 해결되지 않는다. 위 경우에서는 앞선 명령어의 결과값이 ALU의 출력 이후 바로 가져올 수 있었지만, 앞의 명령어가 load 명령어인 경우에는, 메모리에서 읽은 데이터가 유효한 것이 MEM의 끝부터이기에, 이때는 후속 명령어의 EXE 시작 부분에 Data forwarding을 해줄 수 없다.
따라서 불가피하게 후속 명령어들을 잠시 EXE 이전 단계에 머무르게 하여, 앞선 명령어를 기다려주게끔 해야 한다. 이것이 Stall이다.
(아래 사진 참고)

그림의 (a-1)은 stall 없이 data forwarding만 해주는 것이 불가능함을 설명하고 있다.
따라서 (a-2)와 같이 stall 후 data forwarding해 주어야 한다.
“ load 명령어의 destination register와 후속 명령어의 source register가 동일한 경우 stall 신호는 1이 된다.
Control hazard란
“
control hazard는 분기 명령어로 인해 실행 흐름에 변화가 생길 때 발생한다.
위 예시에서, beq 명령어로 인해 실제로 분기될지 여부 (즉 taken 여부)는, EXE 단계에서의 ALU가 't0 - t1'을 연산함으로써 결정된다.
문제는, taken 여부가 결정된 시점에는 이미 이후 명령어들이 실행되고 있었으므로,
"taken이 참이라서 다음 명령어들은 건너뛰어졌어야 하는 경우" 문제가 발생한다.
“
위 경우, 분기 명령어 직후 실행되지 않았어야 하는 명령어들을 flush함으로써 해결할 수 있다.
(아래 사진 참고: 두번째, 세번째 명령어는 flush됨)

IF와 ID 단계에 추가된 mux는 btaken_exe 신호에 따라 정상 control 신호 혹은 nop control 신호 중 선택하며, 후자의 경우 nop은 파이프라인 레지스터를 통해 다음 단계로 흘러가 해당 명령어가 flush됨으로써 건너뛰어지는 것이다.
“
이때 btaken_exe 신호는 어떻게 만들어지는 것인가?
“ 조건 분기 명령어의 경우, ALU 연산 결과에 따라 0 또는 1로 결정되도록, ALU 이후에 로직을 만든다.
“ 그런데 무조건 분기 명령어의 경우에는 언제나 분기를 수행하여 control hazard를 발생시키므로, 일찍이 이것의 ID 단계에서 알아챌 수 있다.
따라서 이러한 무조건 분기 명령어가 ID 단계에 있을 때 jal_id와 같은 control 신호를 만들면, 이는 파이프라인 레지스터를 통해 EXE 단계로 넘어가 jal_exe신호를 만들고, 이는 btaken_exe과 동일하게 작동하여 nop을 발생시킨다.
(아래 사진 참고)

아래는 Data hazard와 Control hazard를 해결하는 (간소화된) 로직이 포함된 CPU 구조이다.

'컴퓨터과학 > 컴퓨터구조와 운영체제' 카테고리의 다른 글
| [Synchronization] Locks(Mutex) (0) | 2024.04.05 |
|---|---|
| [Thread] 스레드 사용의 목적, 스레드 vs 프로세스, 스레드의 자원, 스레드 API (1) | 2024.03.28 |
| [Process] Process의 개념, Address Space, State, Context switch, API (4) | 2024.03.27 |
| [Stack Frame] 프로시저 호출 시의 스택 프레임 살펴보기 (0) | 2024.02.20 |
| Virtual Machine (0) | 2023.04.30 |