Cache Affinity
프로세스가 가능한 한 하나의 CPU에서만 실행되게 하는 것
-> 해당 프로세스의 state가 이미 그 CPU의 cache에 남아있으므로, 다음 번에 프로세스가 실행될 때 훨씬 빨라진다.
만약 cache에 해당 프로세스의 state가 없다면, main memory에서 가져와야 하는데, 이것은 cache에 비해 매우 느림.
💡scheduling 방식
✅SQMS: Single queue Multiprocessor Scheduling
스케줄되어야 하는 job들이 한 queue에 전부 들어가 있다.

단점
- 단일 queue가 여러 CPU에게 공유되어야 하므로 locks가 필요한데, 이 locks는 성능을 크게 떨어뜨리고 scalability가 낮다.
- 프로세스들은 매번(매 time slice마다) 다른 CPU에서 실행되게 되어, cache affinity가 매우 떨어진다.
- 이 문제점을 보완하기 위해, 몇몇 프로세스들을 각각 특정 CPU에 고정하는 방법도 있음. 이때 프로세스의 수가 CPU의 수보다 더 많으면? 일부 프로세스들은 여러 CPU 사이를 migrate해야 함. 다만 이것도 구현이 복잡함.
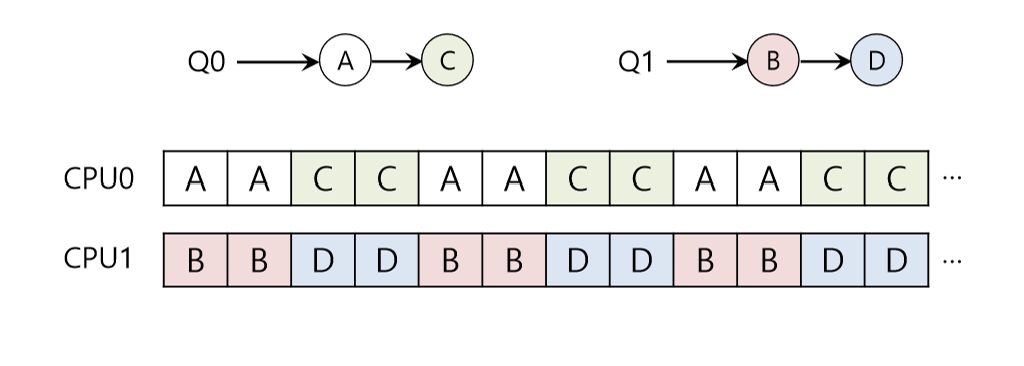
✅MQMS: Multi-queue Multiprocessor Scheduling
한 CPU 당 한 queue를 가지며,
새롭게 도착한 job은 단 하나의 queue에만 들어간다.
장점
- 동기화의 문제가 없어 scalability가 높다.
- job이 한 CPU에 머무를 수 있어 cache affinity가 높다.
load imbalance, migration, work stealing
예를 들어 두 개의 queue에 각각 2개씩의 job이 들어가 있었는데,
만약 한 queue의 하나의 job이 먼저 끝나버리면,
해당 queue의 프로세스는 다른 queue의 프로세스들에 비해 훨씬 오래 실행된다.
심지어, 그마저도 끝나버리면,
해당 queue는 idle해진다.
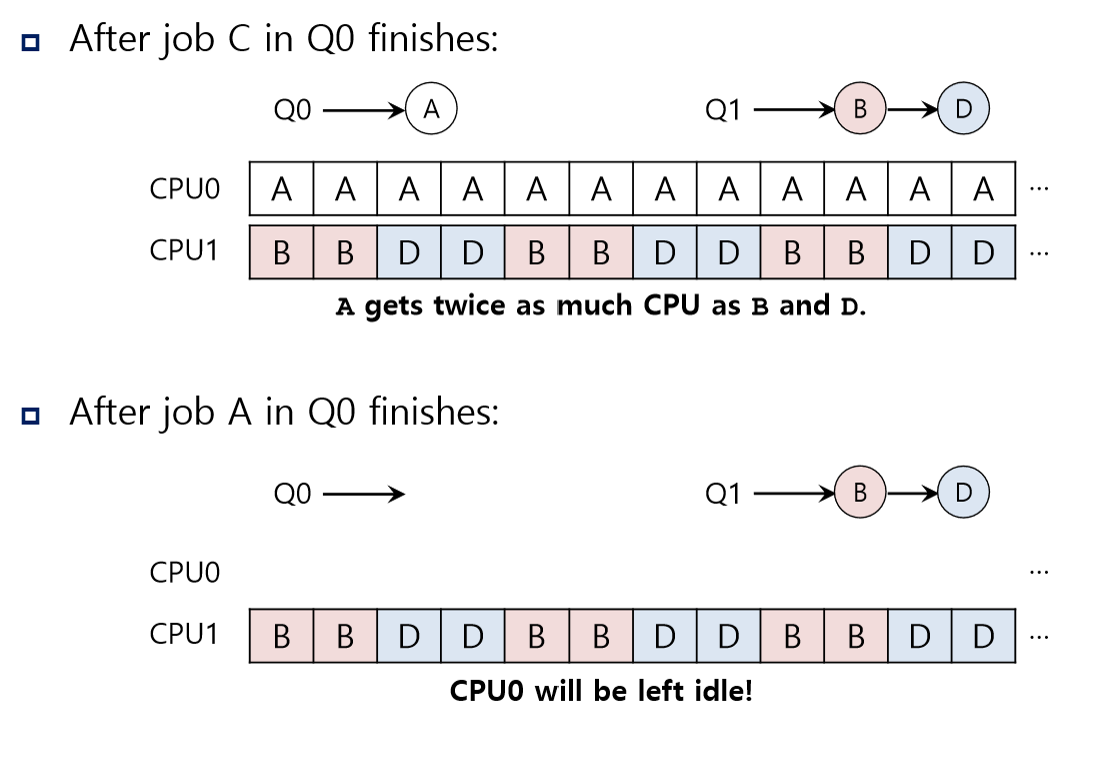
이를 해결하기 위해 아래처럼 migration을 해준다.
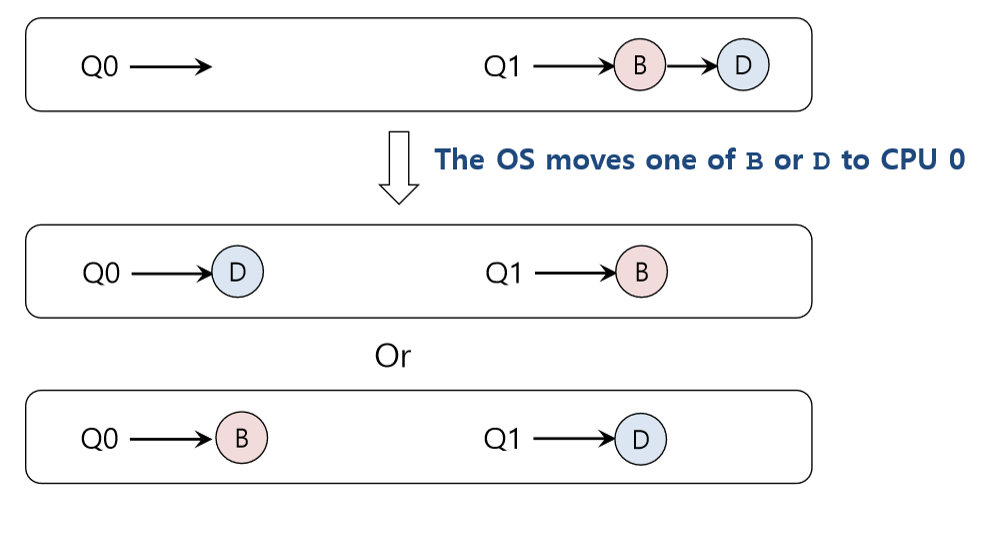
그런데 이와 달리 만약 아래와 같은 상황이라면,

한 번의 migration이 아니라, 아래처럼 중간중간 지속적인 migration을 해주어야 한다.

이때, 시스템이 이러한 migration을 어떤 패턴으로 수행할지 결정하기 위해 work stealing을 활용한다.
비교적 한가한 source queue가 종종 다른 target queue가 얼마나 바쁜지 확인한다.
만약 target queue가 더 바쁘면, soucre queue는 target queue로부터 job(들)을 뺏어옴으로써 load balance를 이룬다.
다만, 이러한 source queue의 곁눈질도 너무 잦아지면 overhead가 심해지니, 적당선을 찾아야 한다.
💡Linux Multiprocessor Schedulers
✅O(1)
- priority-based, Change a process’s priority over time
- multiple queues
- interactivity에 초점을 맞춤
✅CFS: Completely Fair Scheduler
- Deterministic proportional share
- Multiple queues
- sensitive to fairness
✅BFS: Brain Fuck Scheduler
- Proportional-share
- single queue
'컴퓨터과학 > 컴퓨터구조와 운영체제' 카테고리의 다른 글
| [Memory management] Memory virtualization, Dynamic relocation, Segmentation (0) | 2024.05.01 |
|---|---|
| [운영체제란] 운영체제의 역할, HW의 support (0) | 2024.04.21 |
| [Scheduling in single CPU] FIFO, SJF, STCF, RR, MLFQ, Lottery, Stride, CFS (6) | 2024.04.17 |
| [Synchronization] Semaphore (0) | 2024.04.10 |
| [Synchronization] Condition Variables (0) | 2024.04.05 |