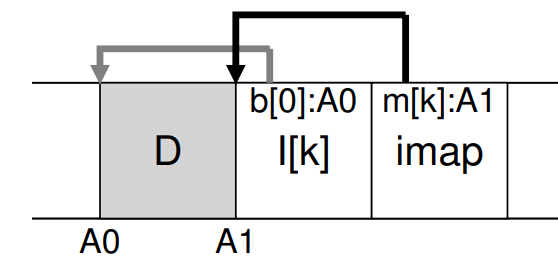
Sequential Write
: 모든 update는 disk에 sequential하게 write한다.
: data block을 disk에 write할 때, sequential하게 Inode와 Inode map도 disk에 write한다.
다만 Sequential write만으로는 최대로 effective하지는 않아서, write buffering 방식도 활용한다.
Write buffering
: one large write
: disk에 write하기 이전에, LFS는 메모리의 update를 추적하고 있다가,
그러한 update가 충분한 개수가 모이면 (이것이 segment이다),
이들을 disk에 "한꺼번에" write함으로써,
disk의 활용이 좀더 효율적이게 된다.
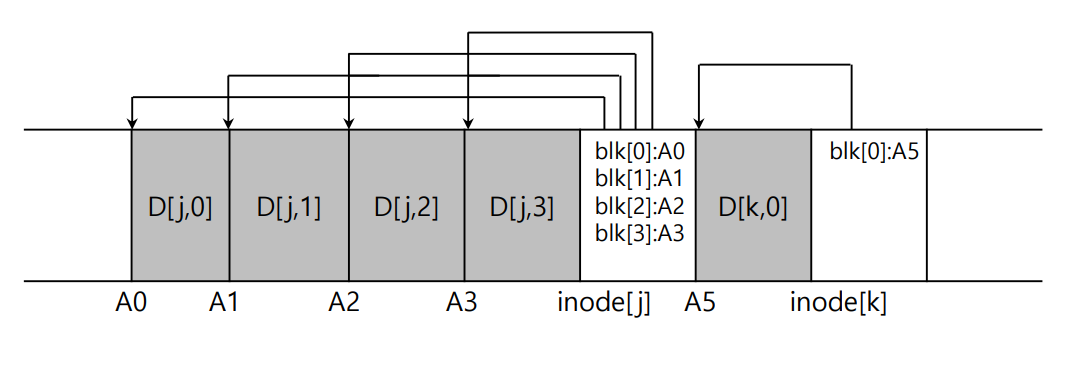
▶example
개별 update는 두번이 있었다: file j에 data block 4개 write, file k에 data block 1개 추가
LFS는 update 때마다 disk에 write하는 게 아니라,
어느 정도 크기 (여기서는 두 update. 이 뭉치가 segment임)가 모였을 때,
이들을 한꺼번에 disk에 commit하는 것이다.
결과적으로 disk layout은 아래처럼 된다.
Segment 크기의 결정
그럼, 대체 한번에 "얼마만큼이 모여야" (= D MB라 하자) disk에 write할 것인가?
요구사항은 다음과 같다: R_effective가 'R_peak의 90%만큼'은 나오게 해주세요!
R_effective = write의 실질적인 속도
R_peak = disk transfer의 최대 속도
F = 여기서는 90%
그럼 D를 구하기 위한 식을 세워보자.
우선, T_write는 당연히 아래와 같다.
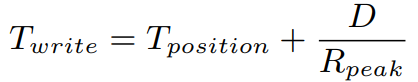
R_effective는 정의상 아래와 같은데,
위 식을 이용해 T_write를 대체한 것이다.
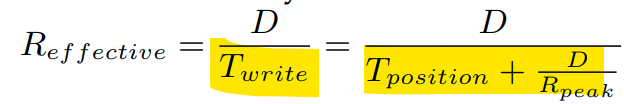
이때 R_effective는 요구사항을 만족하기 위해 F * R_peak여야 하므로,
위 식의 맨 오른쪽 항과 F * R_peak는 같아져, 즉 아래 식을 세운다.
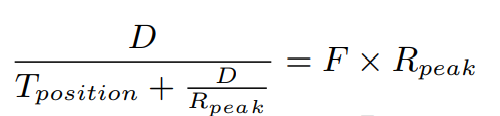
위 식에선 이제, D 말고 다른 값은 다 아는 값이다.
그러니 위 식을 아래와 같이 D에 대해 정리해서 D를 구하는 데 활용할 수 있다.
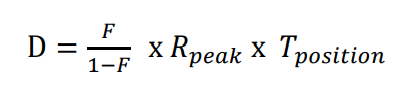
LFS가 File을 read하는 법
read는 sequential이 아니라 random하다.
(-> LFS는 read가 아니라 write에 최적화됨)
read 순서: Checkpoint region -> Inode map -> Inode -> data block
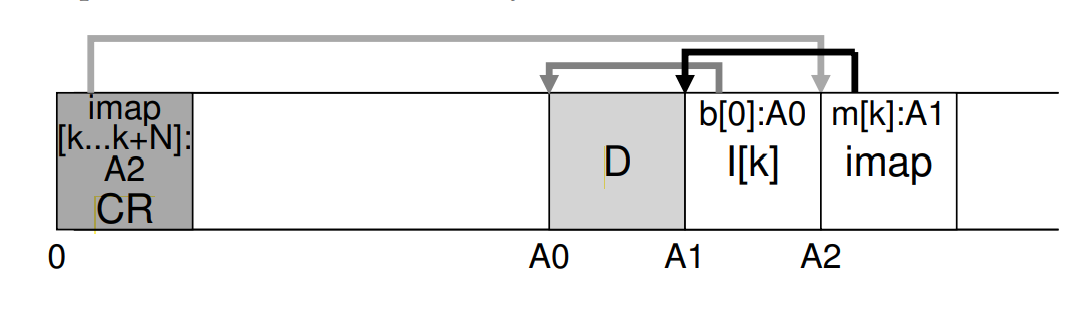

▶Checkpoint Region
Inode map의 가장 최근 버전의 포인터가 들어있음
file lookup을 시작하는 데 필요한 정보는 고정된 위치에 있어야 하는데,
CR은 disk 상의 "고정된" 위치에 있어 쉽게 찾을 수 있음
▶Inode Map
Inode의 가장 최근 버전의 포인터가 들어있음
고정된 위치에 있지 않고, Inode가 새로 disk에 write될 때마다 Imap도 새 위치에 update됨
▶Inode
file/directory의 포인터가 들어있음
Garbage Collection
▶Garbage란
LFS는 새로운 위치에 최신 버전의 flie을 write하기를 반복하고,
이전 버전의 file은 그냥 disk 전반에 흩뿌려져 있는데, 이것이 Garbage이다.
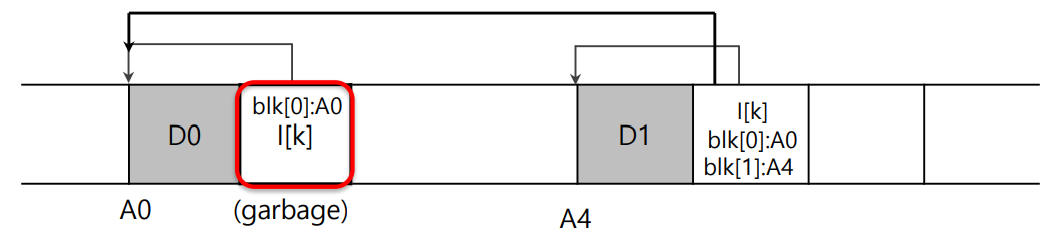
새 data block을 write하는 경우를 생각해보자.
i) 기존의 data block을 overwrite하는 경우
이전의 data block과 inode는 모두 garbage이다.

ii) 기존 data block은 유지하고 새 data block을 append하는 경우
이전의 inode만 garbage이다.
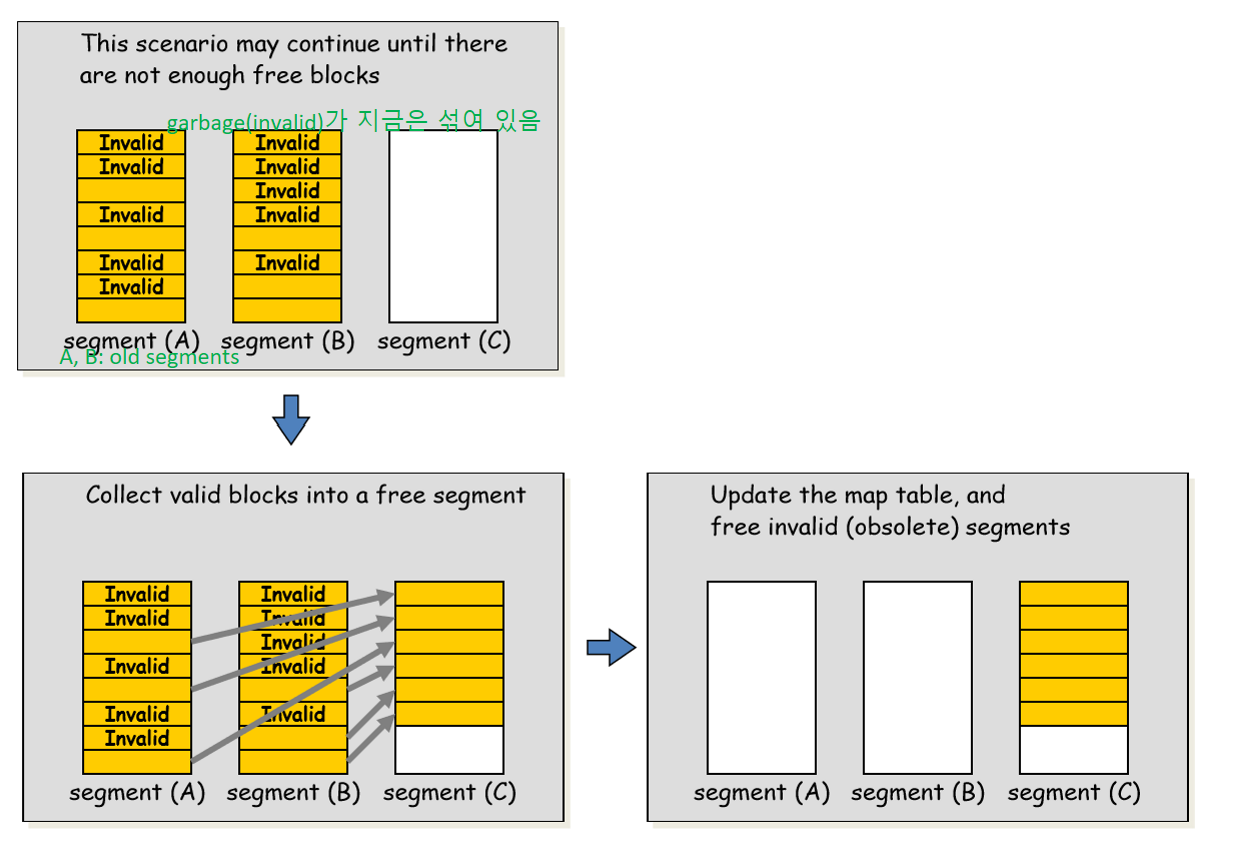
Garbage collection
LFS는 주기적으로 아래 과정을 수행함
i) old segment M개를 read함
ii) 각 segment 내에서 live한 block만을 모아, 메모리 내 new segment N개에 write (N < M)
iii) new segment들은 disk의 새로운 위치에 write
iv) old segment를 free시킴
'컴퓨터과학 > 컴퓨터구조와 운영체제' 카테고리의 다른 글
| [Heap] ptmalloc2(pthread malloc 2) (0) | 2025.01.28 |
|---|---|
| [Heap] chunk의 구조, free list, malloc(), free() (0) | 2024.06.16 |
| [File System] Crash Consistency: FSCK and Journaling (0) | 2024.06.13 |
| [File System] FFS(Fast File System) (0) | 2024.06.13 |
| [File System] VSFS(very simple file system) (0) | 2024.06.05 |