이전 방식 (VSFS)의 문제점
VSFS는 disk를 random access memory로서 다뤘기에, 데이터가 여기저기에 퍼져버림.
이 때문에,
한 파일의 inode와 data block이 너무 멀리 있어서,
파일의 inode를 먼저 읽고 이후에 data block을 읽는 아주 일반적인 동작마저도 상당히 expensive함.
또한, 논리적으로는 연속적인 하나의 파일인데도 물리적으로는 분산돼있을 수 있어서 (아래 그림 참고),
sequential read/write가 불가능하고 disk를 앞뒤로 왔다갔다해야 하니, 성능이 매우 떨어짐.

따라서,
disk 내의 데이터 구조를 어떻게 organize해야 성능을 높일 수 있을지가 문제였다.
FFS의 Cylinder group
FFS는 disk의 물리적 특성을 고려한다.
disk를 여러 개의 cylinder group (현대에는 block group이라 부름)으로 나눈다.
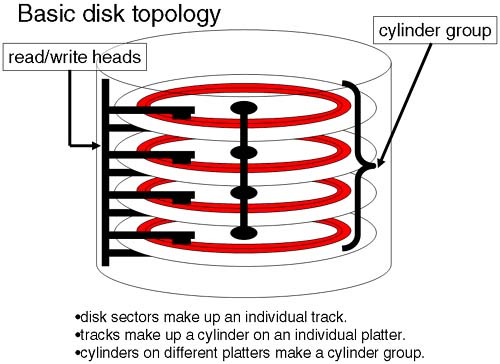
한 cylinder group 내의 구조는 아래와 같다:

FFS의 organizing policy
▶organizing 방식의 모토: "서로 연관된 것들은 함께있게 한다."
즉, 특정 디렉토리와 그 디렉토리의 파일들을 동일한 cylinder group에 놓는다.
▶directory의 placement
할당된 directory의 개수가 작고, free인 inode의 개수가 많은 cylinder group을 찾아,
여기에 directory의 data와 inode를 놓는다.
▶file의 placement
file의 inode가 위치한 그 group에 file의 data를 놓는다.
이로써 모든 file은 자신의 directory와 동일한 group에 놓이고,
한 directory 내의 file들끼리는 가까이에 놓이게 된다.
▶예시를 보자.
group은 10개가 있고, 각 group에는 inode와 data block이 각각 10개라 하자.
이때, directory는 /, /a, /b,
file은 /a/c, /a/d, /a/e, /b/f가 있다 하자.
그러면 아래와 같이 놓여진다.
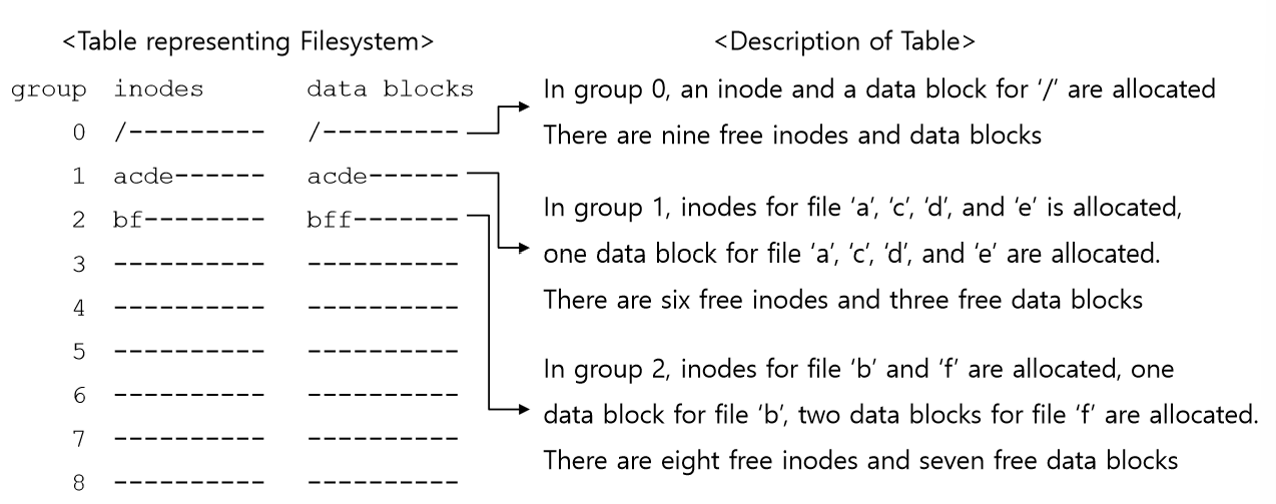
▶FFS policies가 없을 때와 비교하면 아래와 같다.
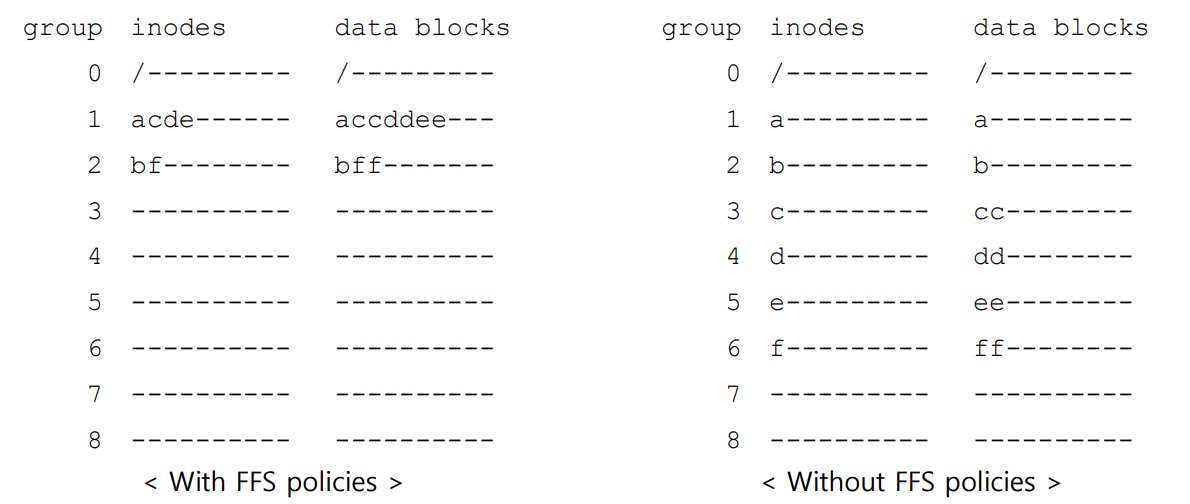
효과
이로써 locality를 활용하게 되어 seek performance가 향상된다.
기존의 API 사용(open(), read(), write(), etc)은 변함없이 내부 구현만 개선한 것이다.
'컴퓨터과학 > 컴퓨터구조와 운영체제' 카테고리의 다른 글
| [File System] LFS(Log-structured File Systems) (0) | 2024.06.14 |
|---|---|
| [File System] Crash Consistency: FSCK and Journaling (0) | 2024.06.13 |
| [File System] VSFS(very simple file system) (0) | 2024.06.05 |
| [File System] File & Directory, Hard link & Soft Link (0) | 2024.06.05 |
| [Secondary Storage] HDD(Hard Disk Drives), RAID(Redundant Array of Inexpensive Disks) (0) | 2024.06.04 |