HDD
Basic geometry



Track skew
track 경계를 건너갈 때일지라도 연속적 read (여러개의 sector read)가 잘 수행되도록.
track skew의 원리가 지하철 환승의 매커니즘과 같다는 생각이 들었다.
내가 1호선에서 2호선으로 갈아탄다 치자.
1호선에서 내린 뒤 2호선이 너무 곧바로 오면,
그 열차는 놓치게 되고, 결국 다음 열차를 위해 배차간격을 거의 통으로 기다려야 한다.
반면, 만약 2호선이 곧바로가 아니라, 아주 센스있게 "내가 1호선에서 2호선으로 걸어갈 여유가 있도록" 약간 딜레이를 두고 와준다면,
나는 2호선 열차를 안전하게 탈 수 있다!
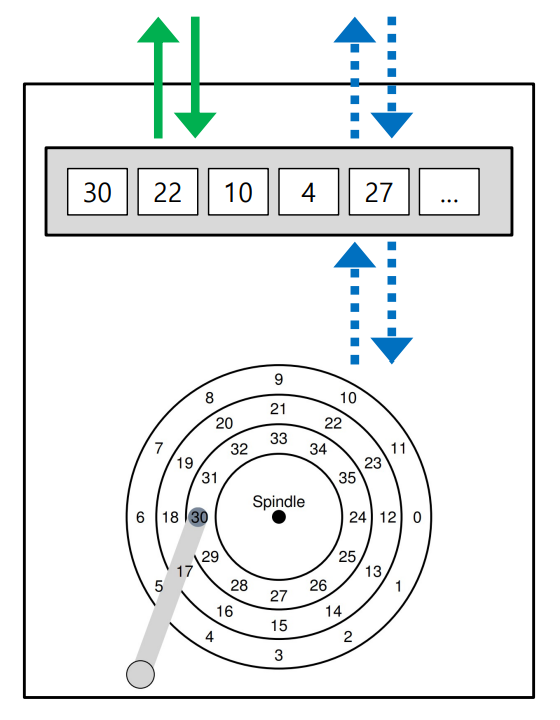
만약 disk가 아래와 같고, 22번과 34번 sector를 순서대로 read하려 한다 치자.
22번을 읽은 뒤, head가 34번으로 띡 옮겨가면 곧바로 34번을 read할 수 있을 것 같지만?
실제로는 아니다.
다른 track으로 옮겨갈 때는, 그게 바로 이웃한 track이라 할지라도, head가 reposition할 시간이 필요하기 때문이다.
그래서 아래와 같은 상황에서는, head가 34번이 있는 track으로 옮겨간 시점에는 이미 34번은 head를 지나쳐있게 되고, 결과적으로 거의 disk의 full rotation을 기다려야 한다.

따라서, track을 옮겨간 head의 reposition 시간까지 고려하여,
track의 상대적 위치를 조정해 34번을 22번의 바로 옆이 아니라 사알짝 나중 위치에 두면,
살짝 뜨는 그 거리 동안에 head는 reposition을 완료하게 되어, 이번엔 정상적으로 34번을 read할 수 있다!

Cache(Track buffer)
8~16MB의 작은 memory이며, drive는 disk에서 read해왔거나 disk에 write될 데이터를 보관해둘 수 있다.
이를 이용해 drive는 request에 빠르게 respond할 수 있다.
Write back vs. Write through
disk에 데이터를 write할 때, 이 write가 완료되었음을 "언제" 인정해줘야 하는가?
1. Write back (= Immediate reporting): 데이터가 "cache에" 놓였을 때
2. Write through: 데이터가 실제로 "disk에" write됐을 때
Performance
Rotation delay

full rotation delay = R이면
30 → 24의 rotation delay = R/2
Seek time

- phases of seek:
acceleration → coasting → deceleration → setting time
I/O Time

I/O Rate
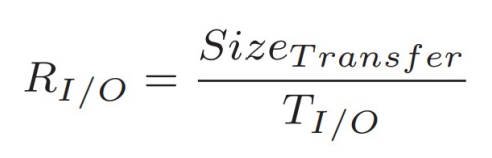
Disk scheduling
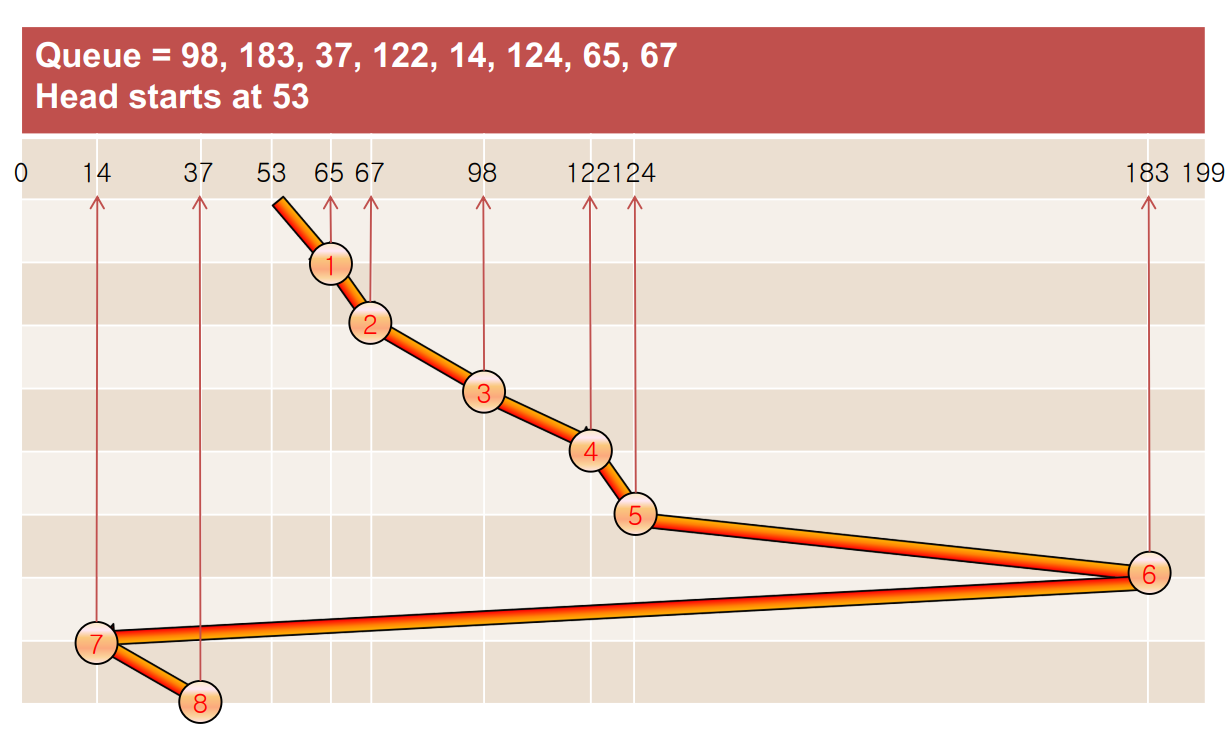
FCFS(First Come First Serve)

- 전체 head 이동: 640 cylinder
SSTF(Shortest Seek Time First)
: 현재 head 위치로부터 가장 작은 seek time을 갖는 reqeust를 선택한다.
- starvation의 위험이 있다.

- 전체 head 이동: 236 cylinder
SCAN(Elevator)
: disk arm이 disk의 양 끝을 왕복하며 request를 처리한다.
- fairness가 안좋음 (→ C-SCAN에서는 개선됨)

- 전체 head 이동: 208 cylinder
C-SCAN
: head가 오직 바깥에서 안쪽 track으로만 쓸고 지나가며 request를 처리한 뒤,
SCAN에서는 이제 반대 방향으로 지나가며 reqeust를 처리했지만, C-SCAN에서는 돌아오는 길에는 request를 처리하지 않고 즉시 바깥 track으로 다시 세팅된다.
- SCAN에 비해 fairness가 좋음: 어느 track이든 좀더 균일한 대기 시간을 가짐 (↔ SCAN은 결과적으로는 중간 위치의 track을 더 선호하게 됨)

C-LOOK
: C-SCAN과 거의 같으나,
여기선 arm이 굳이 양쪽 끝단까지가 아니라, 가장 양끝에 있는 request까지만 간다.
scheduling algorithm의 선택
- 기본값으로 SSTF과 C-LOOK이 적절함
- SCAN, C-SCAN, C-LOOK는 disk의 부하가 큰 곳에서 성능이 좋음
RAID
여러 개의 disk를 하나로 묶어 하나의 논리적 디스크로서 사용함으로써, 빠르고 크고 안정적인 disk 시스템 구축.
- RAID level 0~5가 있음.
RAID level 0
: round-robin 방식으로 striping blocks.
- 가장 단순한 형태
- disk failure에 대처하지 못함
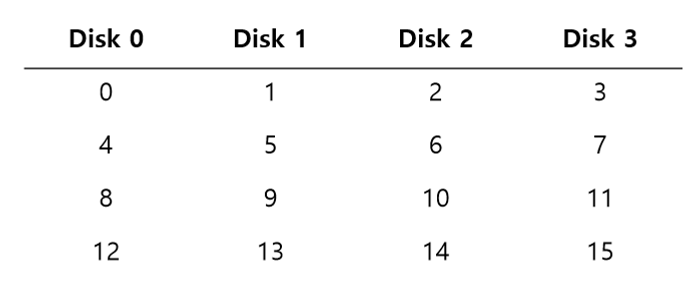
- chunk size를 변경할 수 있음
chunk ↑ ㅡ intra-file parallelism ↓, positioning time ↓
아래는 chunk size가 커진 예시이다: chunk size = 2blocks = 8kB

RAID level 1
: mirroring (각 block을 copy해두고, 이것을 다른 disk에 놓음) → disk failure에 대처
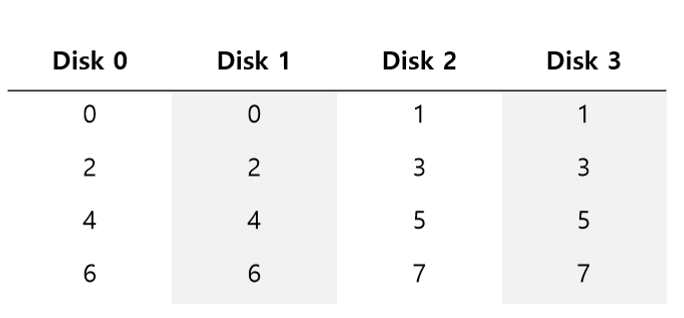
RAID level 4
: parity로서의 disk array 추가됨, full-stripe write(: 5개의 disk에 병렬로 write. 가장 효율적인 방식)
- random write에서 small write problem 있음

RAID level 5
: small write problem의 해결책임. level 4 상태에서 각 stripe를 rotate함

Evaluation
random OR sequential, read OR write operation이 있다.
random read
: random하게 read하므로, disk head의 이동량이 많아 sequential read보다 성능이 떨어짐
VS.
sequential read
: 한번만 움직여도? 많은 sector 읽을수 있음
N: disk 개수, B: 한 disk에서의 block 개수
N * B: 총 block 개수
Reliability: 몇 개의 disk fault까지 견딜 수 있는가

'컴퓨터과학 > 컴퓨터구조와 운영체제' 카테고리의 다른 글
| [File System] VSFS(very simple file system) (0) | 2024.06.05 |
|---|---|
| [File System] File & Directory, Hard link & Soft Link (0) | 2024.06.05 |
| [I/O Devices] I/O Bus, Canonical device, Polling & Interrupt, DMA, MMIO (1) | 2024.06.04 |
| [Memory management] Swapping (0) | 2024.05.23 |
| [Memory management] Paging (0) | 2024.05.13 |