💡write() 이후 과정과 crash
workload example
사용자가 write()를 호출함으로써 이미 있는 파일에다가 data block 하나를 추가하는 workload에서는
Data block 추가, Inode 업데이트, Data bitmap 업데이트
가 이뤄져야 한다.
이들은 disk로 바로 write되지 않고, 일단 main memory의 page cache나 buffer cache에 있다가,
file system이 최종적으로 disk로의 write를 결정하면 그때 disk로 write된다.


crash cases
그럼 crash 상황이란 즉, 위 3개 중 0개 or 1개 or 2개 성공의 상황일 것이다.
이중 애매하게 1개 or 2개만 성공하는 경우 뭔일이 나는지 살펴보자.
▶1개만 성공
여기에도 3가지 경우가 있다.
1) Data block 추가만 성공
consistency에는 문제가 없고, 그냥 write operation이 없었던 것처럼 된다.
2) Inode 업데이트만 성공
read garbage data: 실제로 새 data block에는 write되지 않았는데도, Inode는 해당 data block을 point하므로,
해당 data block 위치에서 garbage data (old contents)를 read하게 돼버린다.
3) Data bitmap 업데이트만 성공
space leak: 업데이트된 bitmap은 새 data block이 (실제론 뭐가 안쓰였는데도) in-use 상태라고 말해주므로, 새 data block은 영원히 사용되지 못한다.
▶2개만 성공
여기에도 3가지 경우가 있다.
1) Data block 추가만 실패
consistency에는 문제가 없지만, 새 data block에 garbage data가 남아있다.
2) Inode 업데이트만 실패
3) Data bitmap 업데이트만 실패
▶Crash-consistency problem
Inode와 Data bitmap 중 하나만 성공하여 둘 간 불일치가 발생할 때 inconsistency가 발생한다.
💡FSCK(File System Checker)
: inconsistency를 찾고 수정하기 위한 Unix 내 tool
- 하지만, 현대 시스템에서 이걸로 recover하기엔 너무 느리다.
💡Journaling(= Write-Ahead Logging)
disk를 업데이트할 때,
최종 disk 위치에 overwrite하기 이전에,
disk의 특정 공간에 Journal(log)(: 어떤 업데이트를 할 것인지)를 미리 써둔다.

만약 crash가 발생하면,
journal이 없을 경우에는 오류 수정을 위해 전체 disk를 스캔해야 하지만,
journal과 함께라면 어디를 어떻게 고쳐야 할지를 정확히 아니까 그것만 재시도하면 된다.
즉, 매 업데이트마다 약간 번거로워지는 대신, crash recovery 시 마주할 거대한 workload를 피하게 되므로,
recovery time이 O(disk의 크기)에서 O(log의 크기)로 감소한다.
한편, journal은 full되지 않고 계속 재사용할 수 있도록 circular log 형태이다.
journal superblock에는 log 내 아직 checkpoint되지 않은 transaction 중 가장 오래된 것과 최신의 것이 무엇인지 기록돼있어서, 이 범위 바깥은 free상태라고 보면 된다.
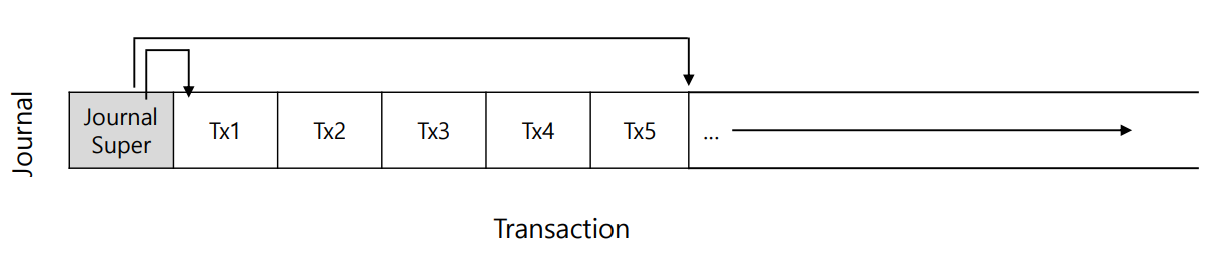
data journaling


TxB: transaction begin block
TxE: transaction end block
I[v2], B[v2]: metadata
Db: Data block
I[v2], B[v2] , Db은 그 자체가 block content이다. (physical logging 방식에서.)
i) Journal write: TxB, I[v2], B[v2], Db를 log에 write
ii) Journal commit: TxE를 log에 write → commited
iii) Checkpoint: I[v2], B[v2], Db를 최종 disk 위치에 write
iv) Free: journal superblock을 update함으로써, journal 내의 완료된 transaction이 차지하던 공간을 free시킴
※ TxE의 write만 나중에 따로 하는 이유
"Journal write 단계" 도중에 발생하는 crash에 대응하기 위한 방법을 살펴보자.
i) TxB, I[v2], B[v2], Db, TxE을 한번에 한개씩만 transaction
→ 느려터짐
ii) 한꺼번에 write
→ 위 다섯개 write 순서가 안지켜질수도 있음
→ 만약 순서 꼬여 Db 빼고 다 write한 뒤 Db write 이전에 crash 발생하면,

위와 같이, 겉으로 보기엔 어쨌든 TxB와 TxE는 멀쩡히 write돼있는 멀쩡한 transaction이기에,
추후 reboot 이후 recovery system이 이 transaction을 replay함으로써,
아직 Db가 write되지 않아 그자리에 차있는 garbage를 disk의 Db 자리에 write해버릴 수도 있다.
iii) transaction의 end를 의미하는 TxE는 일단 제쳐두고, 나머지부터 얼른얼른 journal에 한꺼번에 write한 뒤,
다 끝나고 나서 이제 맘놓고 TxE를 write함으로써, atomicity를 보장한다.
→ good!
∴ iii)에 따라 TxE만 따로 나중에 write한다.
metadata journaling
data journaling은 data block을 한번 disk에 write할 때마다 그전에 journal에도 write해야 하기에,
write traffic이 두배가 되는 문제가 있다.
그래서, 거의 동일한 방식이지만 Db는 journal에 적지 않는 metadata journaling 방식이 있다.
이로써 I/O load가 많이 감소한다.


i) Data write: Db을 최종 disk 위치에 write (journal에의 write 없이 바로.)
ii) Journal metadata write: TxB, I[v2], B[v2]를 log에 write
※ i), ii)는 동시에 일어나도 되며, iii) 이전에만 완료되면 됨
iii) Journal commit: TxE을 log에 write → commited
iv) Checkpoint metadata: I[v2], B[v2]를 최종 disk 위치에 write
v) Free: journal superblock 내에서, 완료한 transaction을 free시킴
Recovery step
▶Journal commit 완료 이전에 crash난 경우
그냥 update 자체를 안하면 해결됨
▶Journal commit 이후 ~ Checkpoint 완료 이전에 crash난 경우
redo logging
: 시스템 boot 시, file system recovery process가 log를 스캔하며 disk에 commit된 (그러나 checkpoint에는 실패한) transaction을 찾고,
이들을 순서대로 replay, 즉 file system이 해당 commit들을 최종 disk 위치에 write한다.
'컴퓨터과학 > 컴퓨터구조와 운영체제' 카테고리의 다른 글
| [Heap] chunk의 구조, free list, malloc(), free() (0) | 2024.06.16 |
|---|---|
| [File System] LFS(Log-structured File Systems) (0) | 2024.06.14 |
| [File System] FFS(Fast File System) (0) | 2024.06.13 |
| [File System] VSFS(very simple file system) (0) | 2024.06.05 |
| [File System] File & Directory, Hard link & Soft Link (0) | 2024.06.05 |