TF-IDF의 계산 과정
✅DTM(Document-Term Matrix): 각 문서들 (행)에서 각 단어들 (열)이 등장한 횟수가 담긴 행렬
여기서 문서를 d, 단어를 t, 문서의 총 개수를 n이라고 하겠다. 그러면...
✅tf(d,t): 특정 문서 d에서의 특정 단어 t의 등장 횟수. (= DTM의 각 셀의 값)
✅df(t): 특정 단어 t가 등장한 문서의 수.
✅idf(t): df(t)에 (대략) 반비례하는 수.
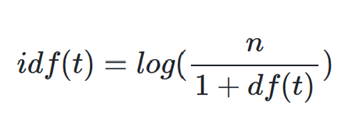
✅TF-IDF: TF와 IDF를 곱한 값.
TF-IDF의 강점
DTM에 비해 TF-IDF는 각 단어의 중요성도 반영하여 처리한다는 강점이 있다.
TF의 역할: 어떤 단어가 특정 문서에서 많이 등장했다면 가중치를 높혀줌
IDF의 역할: 어떤 단어가 많은 문서에서 등장했다면 가중치를 낮춰줌 ∵ df(t)가 커지면 idf(t)는 작아지므로
👉 모든 문서에서 자주 등장하는 단어는 중요도가 낮고, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
'컴퓨터과학 > 인공지능' 카테고리의 다른 글
| 초거대AI가 불러온 변화와 우리의 대응전략 (네이버클라우드 하정우센터장님) (0) | 2024.07.01 |
|---|---|
| [논문] Improving Performance of Autoencoder-Based Network Anomaly Detection on NSL-KDD Dataset (1) | 2024.05.31 |
| [Naive Bayes Algorithm] 원리, 종류, 주의사항 (0) | 2024.05.11 |
| 작성중 (0) | 2023.07.30 |
| [Object Detection / Recognition / Tracking] Feature Extraction 기법: SIFT, SURF, ORB (1) | 2023.07.29 |