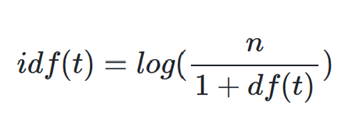[Naive Bayes Algorithm] 원리, 종류, 주의사항
Naive Bayes Algorithm의 원리 E2가 참일 때, E1도 참일 확률 (즉, 조건부 확률)은 아래와 같다. 위 원리를 이용하여,feature X가 만족되었을 때, class Ck일 확률은 아래와 같다. 이때, 보통 이 feature는 하나가 아니라 여러 개이므로, 이를 반영하면 아래와 같다. eg) 날씨&온도&습도&바람에 따라 사람들이 테니스를 칠지/안칠지 예측하는 문제 여기서, Naive Bayes Algorithm은 각 feature가 독립적이라고 가정하므로, 위 식은 아래와 같이 바꿀 수 있다.아래가 Naive Bayes Algorithm의 최종 공식이다. Naive Bayes Algorithm의 종류 ✅Gaussian Naive Bayes변수가 conti..