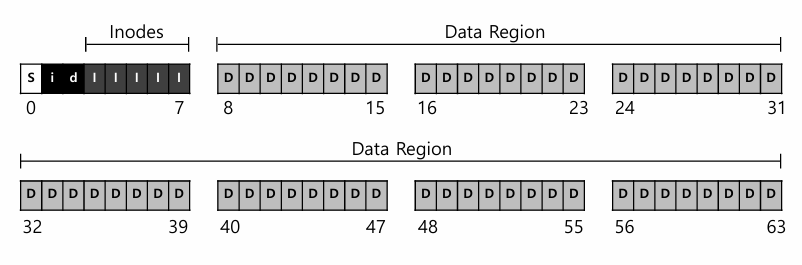
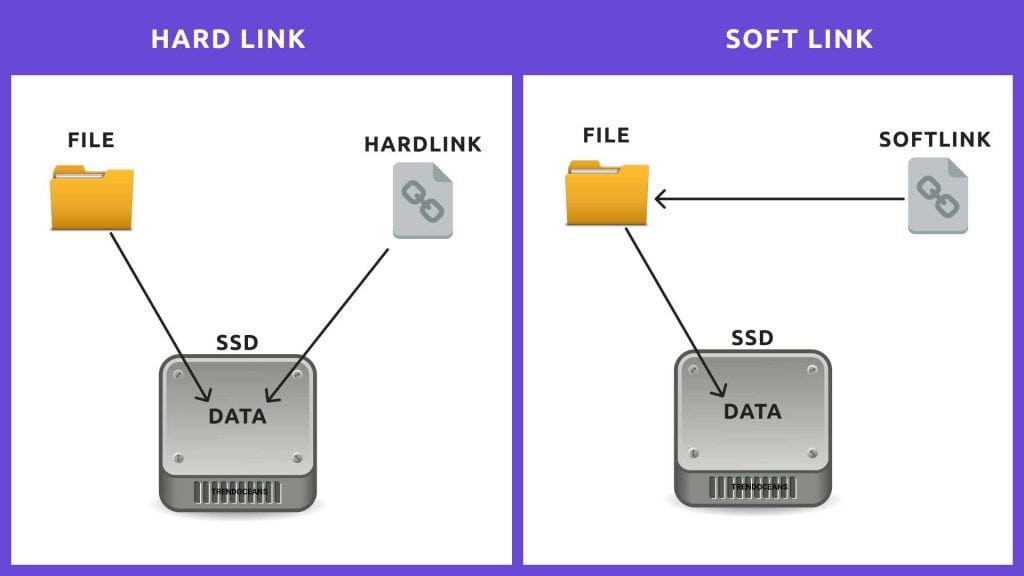
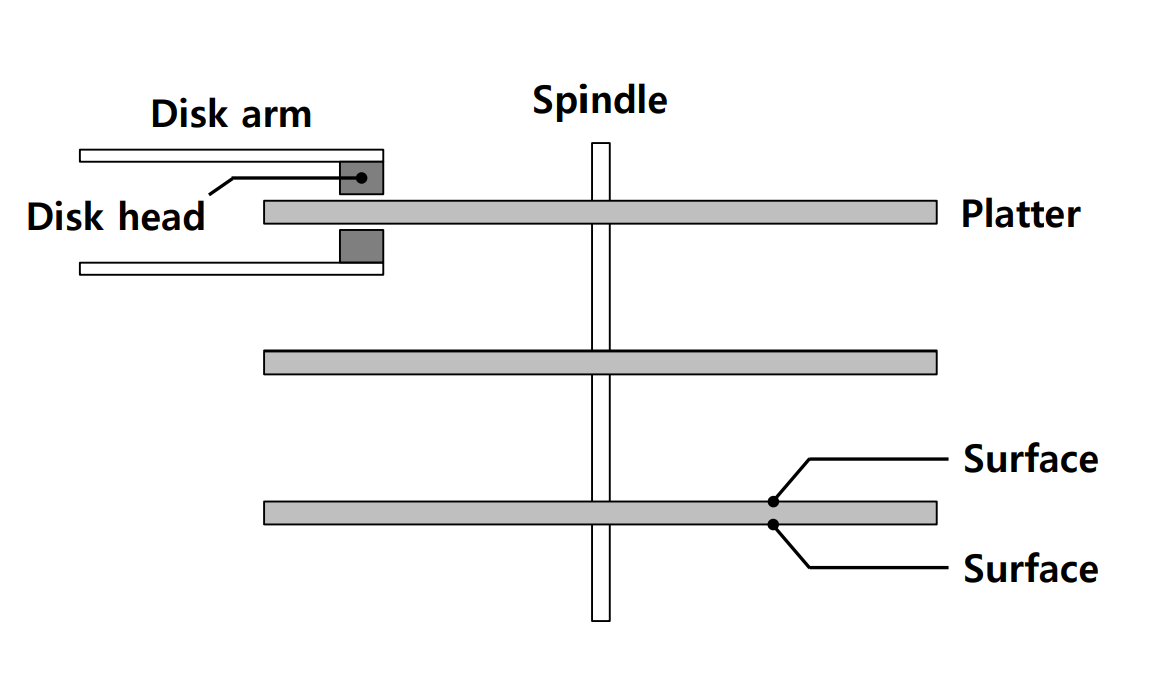
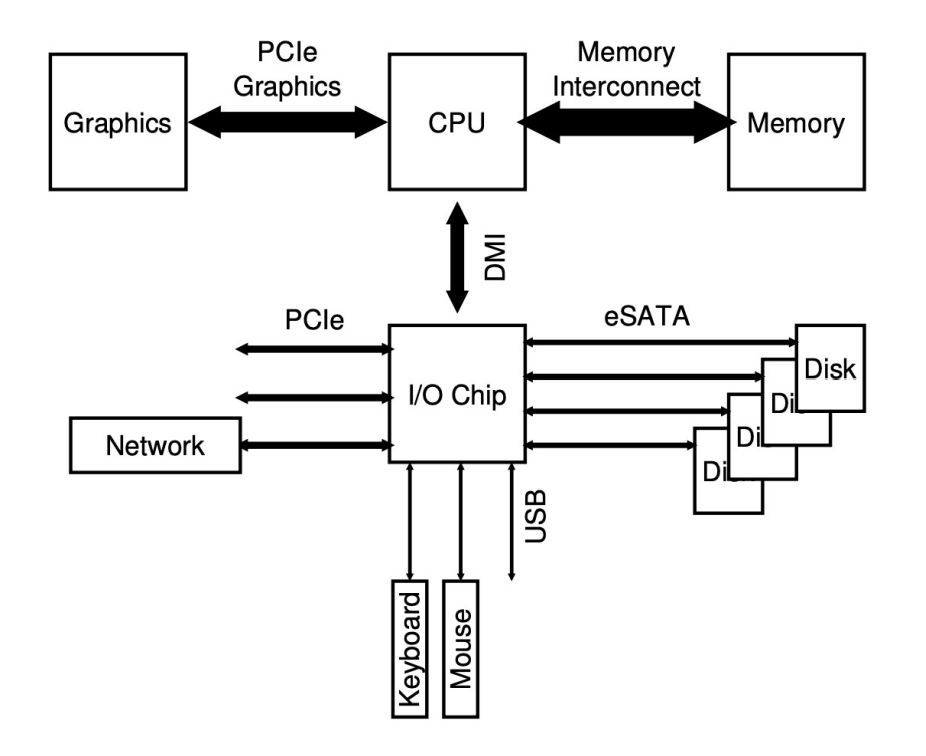
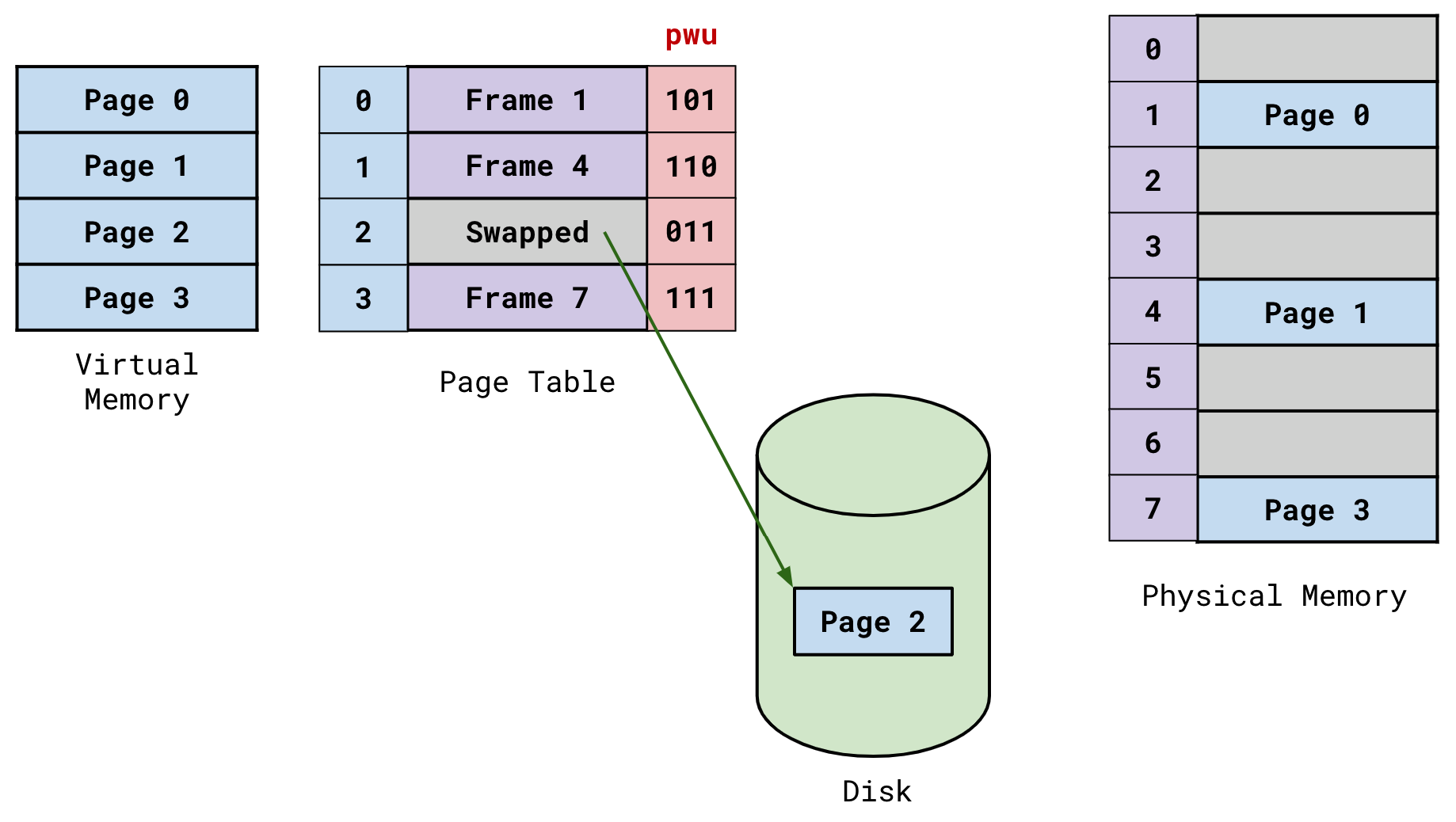
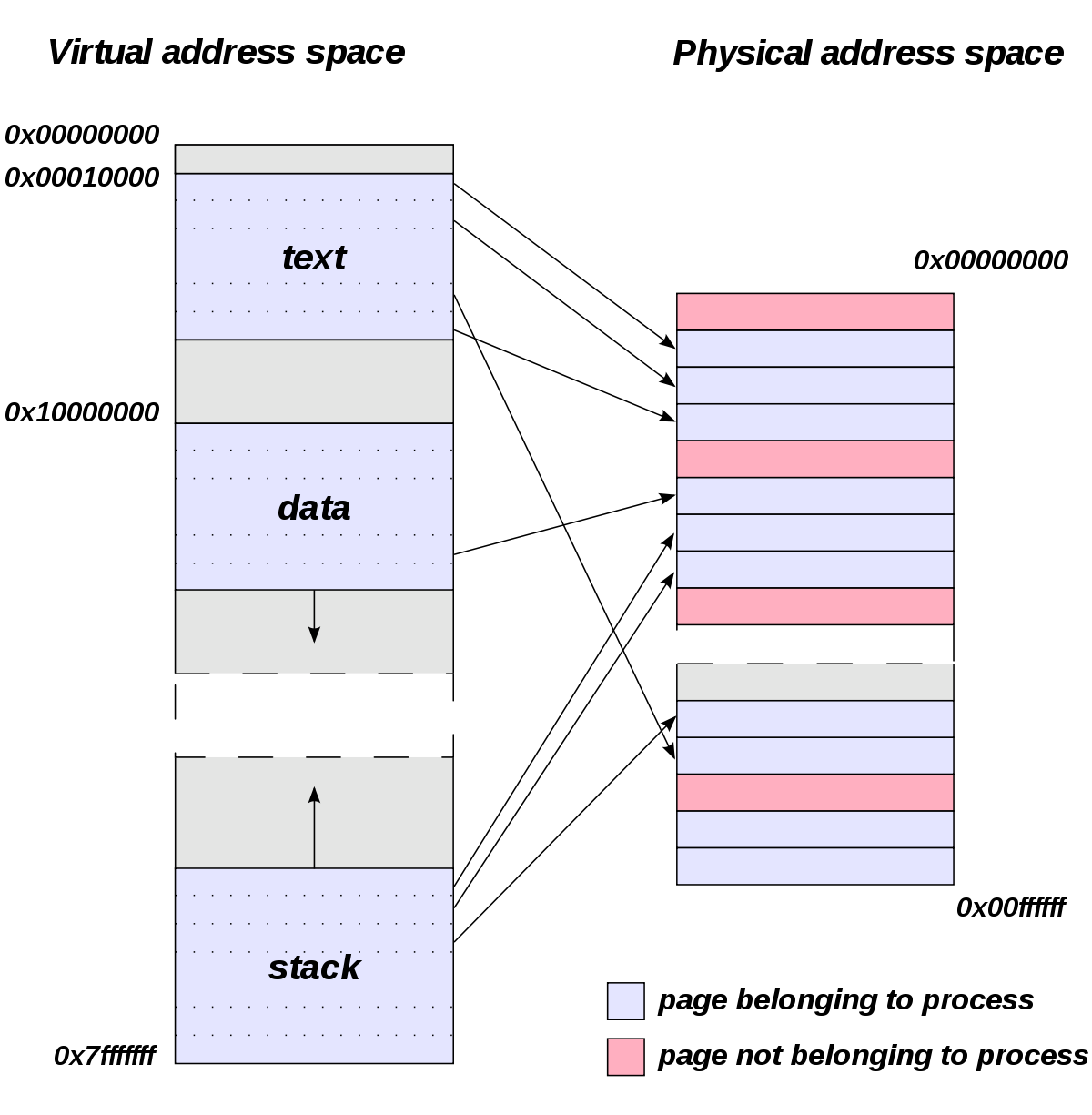
overall organization▶block: 위 사진에서 각각의 작은 네모 하나. 4kB ▶Data region: user data 저장 ▶Inode: 파일의 주요 metadata 정보 (파일이 나뉘어있는 data block이 어떤건지, 파일 크기, 소유자, 파일에 대한 접근 권한과 접근/수정 시간 등)를 track하기 위해 이들이 저장된 곳- inode number에 의해 위치가 계산되어 refer- 위 사진의 Inode table에서 주황색 네모 하나. 256B- 위 사진 기준으로는 Inode가 총 80개이므로, 가능한 최대 파일 개수도 80개이다. ▶Inodes(Inode table): Inode의 array임 ▶Bitmap: Inode나 Data block의 free(0) / alloca..